ESPnet Recipe Instructions
0. Installation
For PSC usage and kaldi/espnet installation, please refer to this wiki.
1. Introduction
In this section, we will provide an overview of one the core parts of ESPnet, the recipes, and introduce their format.
1.1. What is a recipe ?
First you need to define the speech task that you want to perform and the corpus that you want to use for this task. Let’s call our task “task” and our corpus “corpus”. As an exemple, we can have task = asr(Automatic Speech Recognition) and corpus = librispeech.
A recipe is a folder containing all the scripts to download and prepare the data of corpus, train a task model on this prepared data, and evaluate it’s performances.
The different stages of the recipe should be easily executable with bash instructions shared for all recipes detailed later in this wiki. In ESPnet2, recipes that train models on the same task share most parts of their codes, using calls to shared scripts.
1.2. What is Kaldi-style ?
ESPnet2 recipes follows Kaldi-style for their recipes. Kaldi is a toolkit for speech recognition written in C++. Kaldi is intended for use by speech recognition researchers.
To create a recipe, we only have to focus on one of Kaldi’s top-level directories : egs. egs stands for ‘examples’ and contains the recipes for a lot of corpora.
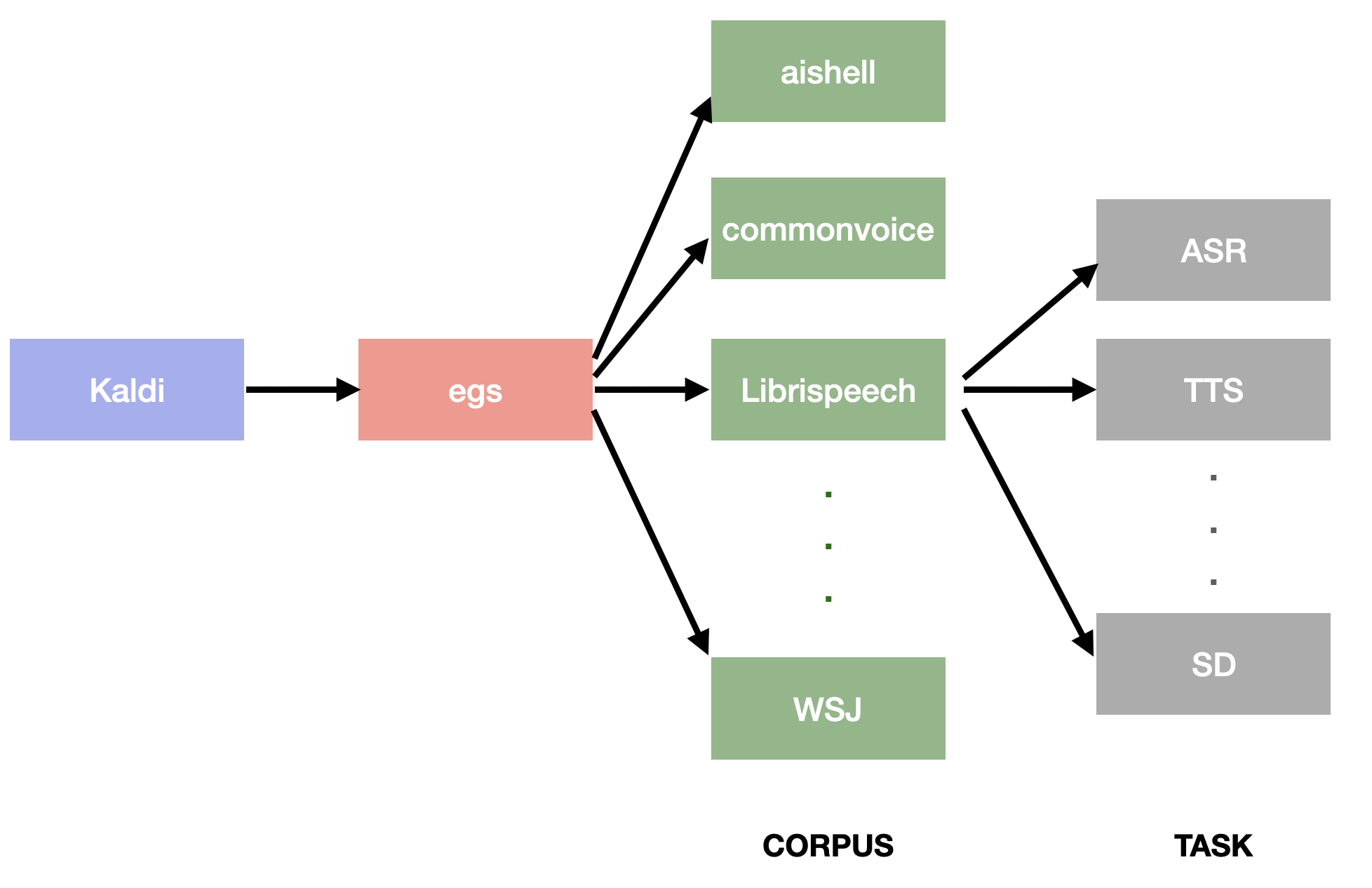
ESPnet follows the same architecture than Kaldi so you will find the directories in ESPnet. The folder for ESPnet2 examples is egs2/.
1.3. ESPnet2
ESPnet2 is a newer version of ESPnet. Contrary to Kaldi, it provides shared bash files for recipes to enable generic stages and states during the process. For instance, if there are 2 asr recipes, one on Librispeech corpus, and the other on aishell corpus, the directories egs2/Librispeech/asr/ and egs2/aishell/asr/ will call the generic asr.sh file.
2. Main steps
2.1. Shared files and folders
Most of the files and folders are shared with all ESPnet2 recipes. You can just copy them into your recipe’s folder and use symbolic links (command : ln -s {source-filename} {symbolic-filename}). In the following, we will point out the specific files that you need to modify for your recipe.
2.2. Important files to write
2.2.1. Call the generic asr.sh : run.sh
You have to write corpus/task/run.shfile, for instance aishell/asr/run.sh.
The role of this file is to call the generic task file, for instance the generic asr.sh file with specific arguments of your recipe.
After few lines defining variables, your file should look like this :
./asr.sh \
--lang zh \
--audio_format wav \
--feats_type raw \
--token_type char \
--use_lm ${use_lm} \
--use_word_lm ${use_wordlm} \
--lm_config "${lm_config}" \
--asr_config "${asr_config}" \
--inference_config "${inference_config}" \
--train_set "${train_set}" \
--valid_set "${valid_set}" \
--test_sets "${test_sets}"
As all preparation and training stages are performed through the generic file (here asr.sh), the run.sh file is a short file.
For more details you can have a look at any recipe’s run.sh file (aishell, commonvoice …).
2.2.2. Prepare the data : local/data.sh
This will probably be your first and most complicated task. As each recipe comes with its own data, there is no generic file for this part.
The file should handle data download and preparation. Starting from no data, you should get a folder like this after executing the local/data.sh file. We used the template of ESPnet repo in this section.
data/
train/
- text # The transcription
- wav.scp # Wave file path
- utt2spk # A file mapping utterance-id to speaker-id
- spk2utt # A file mapping speaker-id to utterance-id
- segments # [Option] Specifying start and end time of each utterance
dev/
...
test/
...
- Directory structure
data/ train/ - text # The transcription - wav.scp # Wave file path - utt2spk # A file mapping utterance-id to speaker-id - spk2utt # A file mapping speaker-id to utterance-id - segments # [Option] Specifying start and end time of each utterance dev/ ... test/ ... textformatuttidA <transcription> uttidB <transcription> ...wav.scpformatuttidA /path/to/uttidA.wav uttidB /path/to/uttidB.wav ...utt2spkformatuttidA speakerA uttidB speakerB uttidC speakerA uttidD speakerB ...spk2uttformatspeakerA uttidA uttidC ... speakerB uttidB uttidD ... ...Note that
spk2uttfile can be generated byutt2spk, andutt2spkcan be generated byspk2utt, so it’s enough to create either one of them.utils/utt2spk_to_spk2utt.pl data/train/utt2spk > data/train/spk2utt utils/spk2utt_to_utt2spk.pl data/train/spk2utt > data/train/utt2spkIf your corpus doesn’t include speaker information, give the same speaker id as the utterance id to satisfy the directory format, otherwise give the same speaker id for all utterances (Actually we don’t use speaker information for asr recipe now).
uttidA uttidA uttidB uttidB ...-
[Option]
segmentsformatIf the audio data is originally long recording, about > ~1 hour, and each audio file includes multiple utterances in each section, you need to create
segmentsfile to specify the start time and end time of each utterance. The format is<utterance_id> <wav_id> <start_time> <end_time>.sw02001-A_000098-001156 sw02001-A 0.98 11.56 ...Note that if using
segments,wav.scphas<wav_id>which corresponds to thesegmentsinstead ofutterance_id.sw02001-A /path/to/sw02001-A.wav ...
3. Shared files description
As the shared task files (asr.sh, tts.sh …) handle most of the important steps in ESPnet2, it is important to know how they are built. The shared files are built with stages.
3.1. asr.sh
asr.sh contains 15 stages.
Overview :
- stage 1 to stage 5 : data preparation stages
- stage 1 : call to your own data.sh file
- stage 2 : speed perturbation modification of inputs
- stage 3 : create a dump folder, segment audio files, change the audio-format and sampling rate if needed. This step enables to get a common format for files which enable combining different corpora at training or inference time.
- stage 4 : remove short and long utterances
- stage 5 : generate a token list (can be word level, character level or bpe level)
- stage 6 to stage 8 : Language Model stages
- stage 6 : preparing LM training
- stage 7 : train the LM (needs GPU)
- stage 8 : calculates perplexity
- stage 9 to stage 11 : ASR training steps
- stage 12 to stage 13 : Evaluation stages : decoding (stage 12) and scoring (stage 13)
- stage 14 to stage 15 : model uploading steps, upload your trained model through those two final steps